

SqlDBM for BI developers, BI consultants and data architects
Create, modify and maintain your cloud-based data warehouse
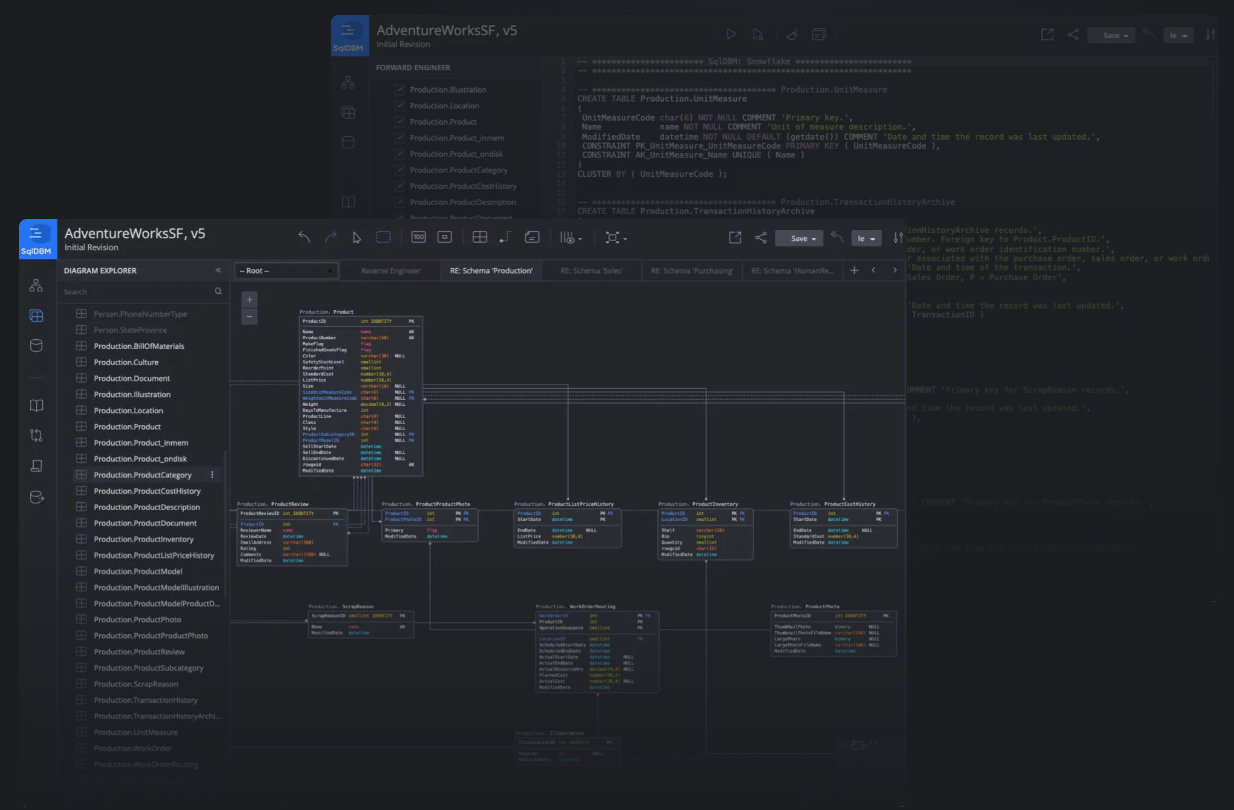
Use SqlDBM for Snowflake, Synapse and Redshift
SqlDBM helps to develop or transition to any of the supported cloud-built data warehouses such as Snowflake, Synapse, and Redshift. Whether you want to migrate your existing enterprise data warehouse and data lake or build a new data warehouse, SqlDBM’s functionality is designed for the BI professionals and it provides all users with cutting-edge capabilities. And all that without writing a single line of code.

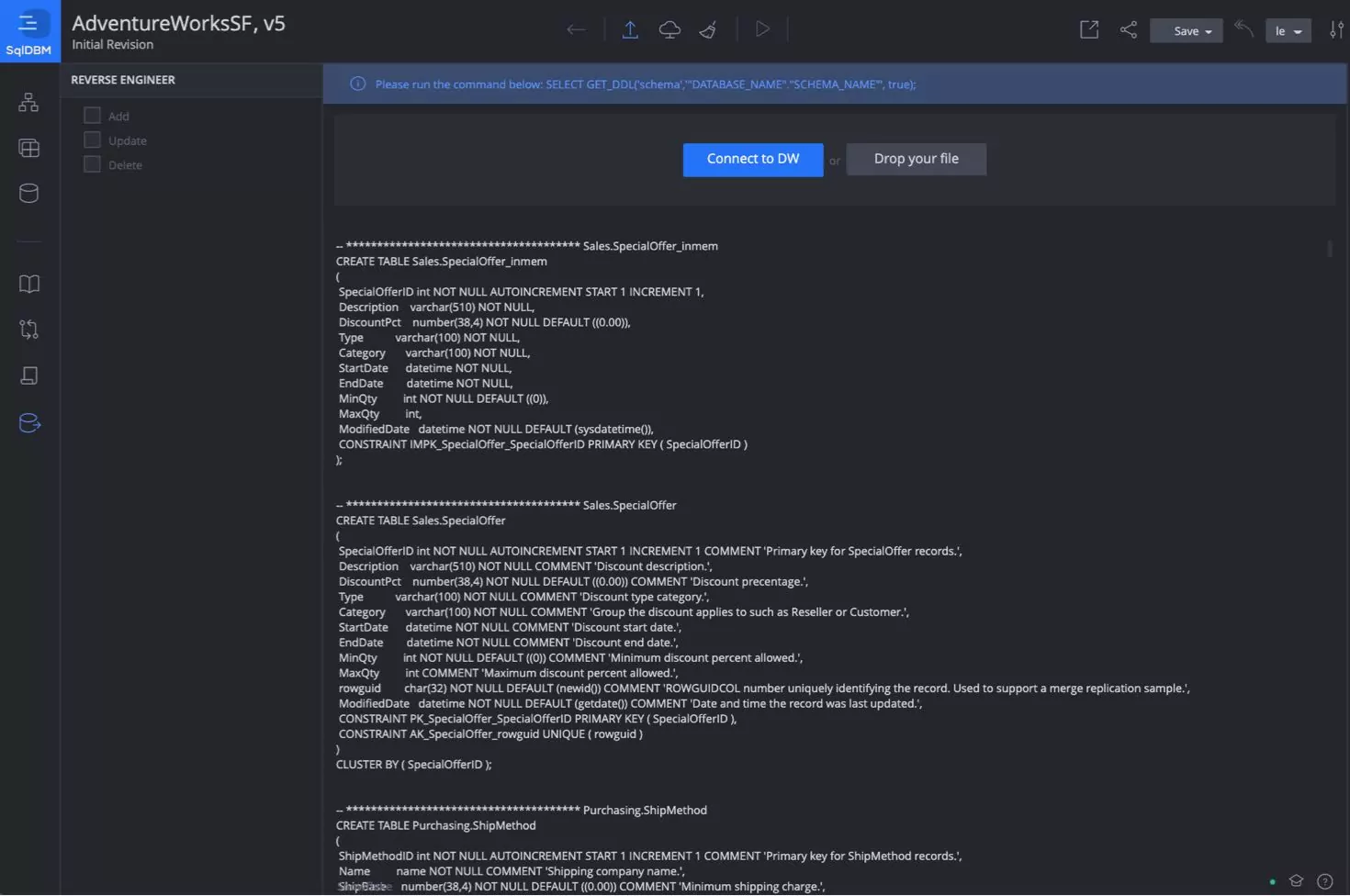
Data warehouse with forward & reverse engineering
Design and forward engineer all objects from your model into the cloud-based data warehouse of your choice. Use the SqlDBM reverse engineering feature to produce a graphical representation of your data warehouse objects and the relationships between them. Make appropriate modifications and then export back to the data warehouse.
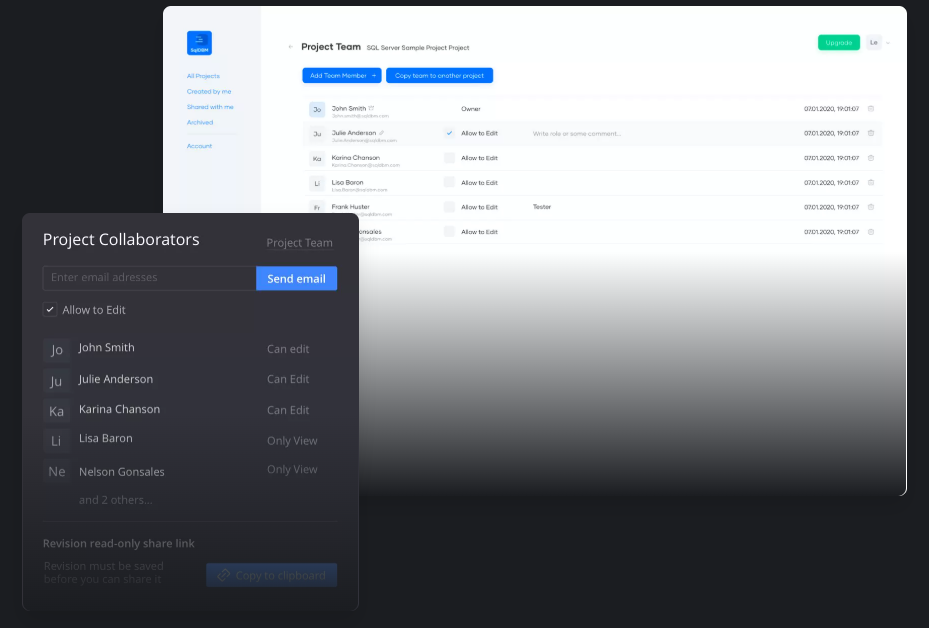
Collaborate with your team
Work remotely with your team and stakeholders on the same project. Keep a geographically dispersed team collaborating and always in sync.
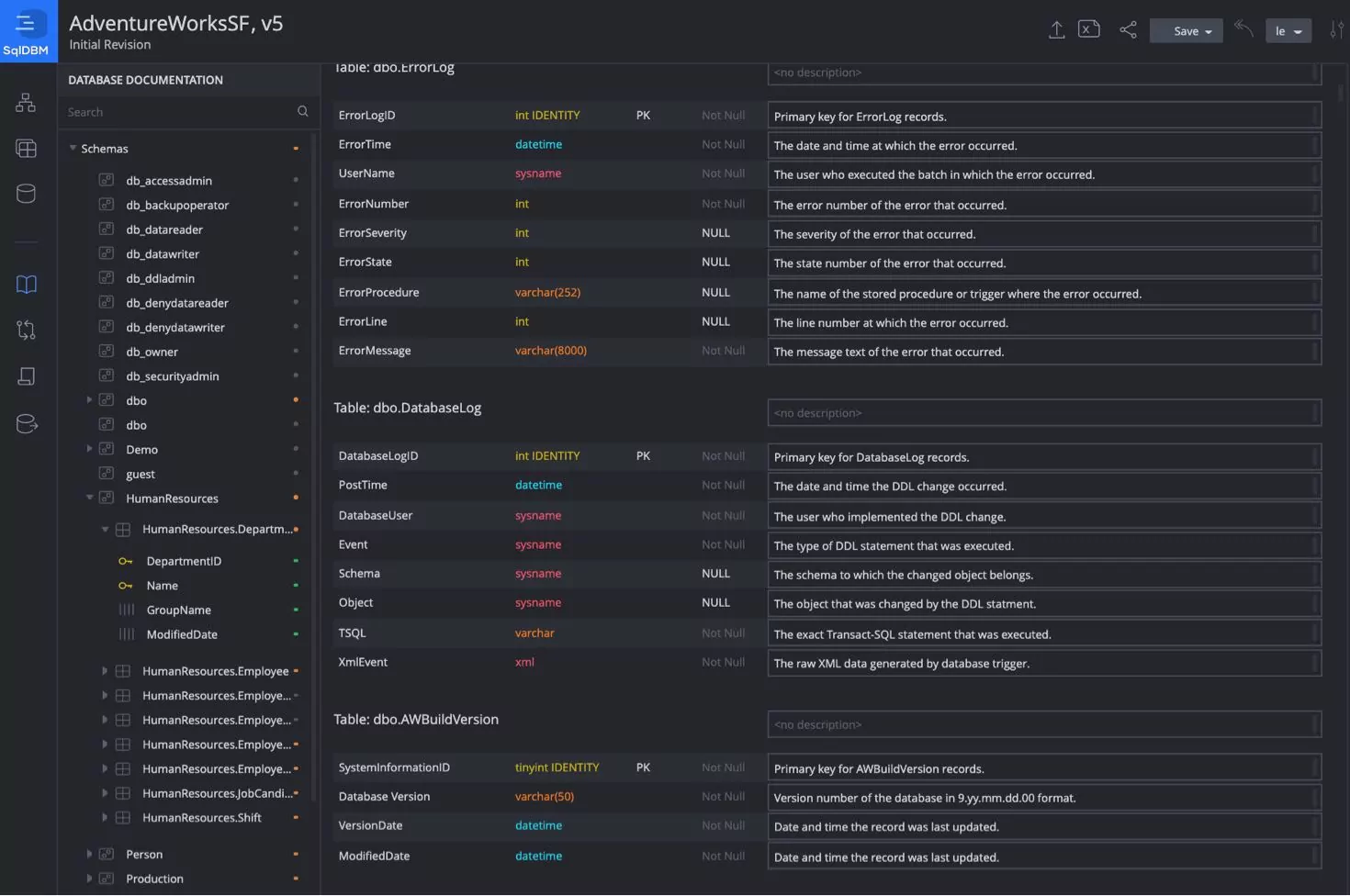
Document your data warehouse and share with business users
In order to fully support model governance and business intelligence efforts in your organization – SqlDBM enables you to document, share and export any data definitions in your data warehouse for consistency, clarity and artifact reuse across large-scale data integration, master data management, data quality, metadata management, Big Data, and analytics initiatives.
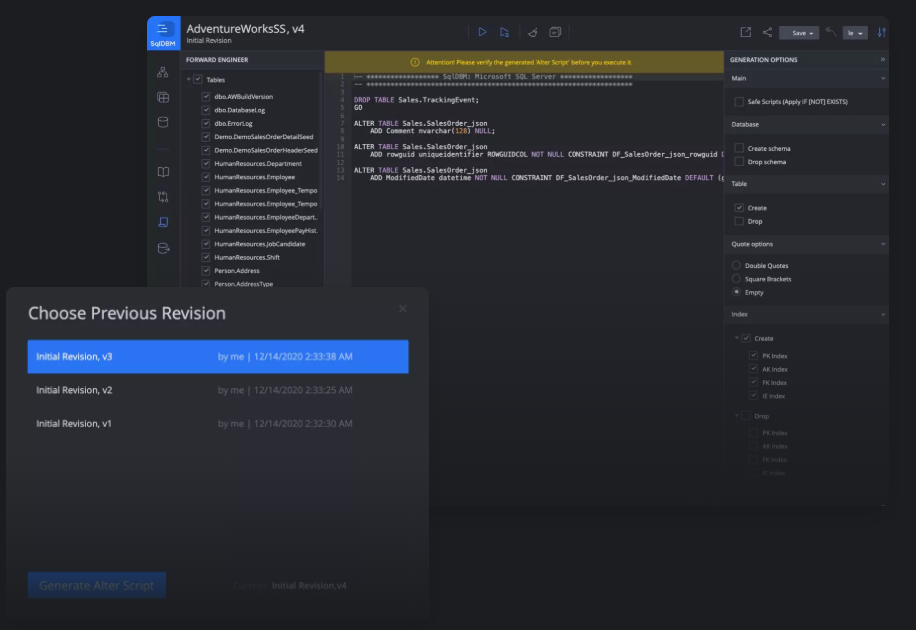
Complete data warehouse development lifecycle with alter script
SqlDBM provides the alter script feature that helps to incorporate the changes to the already existing database/data warehouse design. This is vital to ensure that your database can be easily kept up-to-date with your ever-evolving data model. Apply alter script on a model to synchronize changes SqlDBM and your database.
Trusted by data teams globally
400,000+ users globally












